Fitting a distribution in Stan from scratch
Last week the French National Institute of Health and Medical Research (Inserm) organised with the Stan Group a training programme on Bayesian Inference with Stan for Pharmacometrics in Paris.
Daniel Lee and Michael Betancourt, who run the course over three days, are not only members of Stan’s development team, but also excellent teachers. Both were supported by Eric Novik, who gave an Introduction to Stan at the Paris Dataiku User Group last week as well.
 |
| Eric Kramer (Dataiku), Daniel Lee, Eric Novik & Michael Betancourt (Stan Group) |
I have been playing around with Stan on and off for some time, but as Eric pointed out to me, Stan is not that kind of girl(boy?). Indeed, having spent three days working with Stan has revitalised my relationship. Getting down to the basics has been really helpful and I shall remember, Stan is not drawing samples from a distribution. Instead, it is calculating the joint distribution function (in log space), and evaluating the probability distribution function (in log space).
Thus, here is a little example of fitting a set of random numbers in R to a Normal distribution with Stan. Yet, instead of using the built-in functions for the Normal distribution, I define the log probability function by hand, which I will use in the model block as well, and even generate a random sample, starting with a uniform distribution. However, I do use pre-defined distributions for the priors.
Why do I want to do this? This will be a template for the day when I have to use a distribution, which is not predefined in Stan, e.g. the actuar package has some interesting candidates.
Testing
I start off by generating fake data, a sample of 100 random numbers drawn from a Normal distribution with a mean of 4 and a standard deviation of 2. Note, the sample mean of the 100 figures is 4.2 and not 4.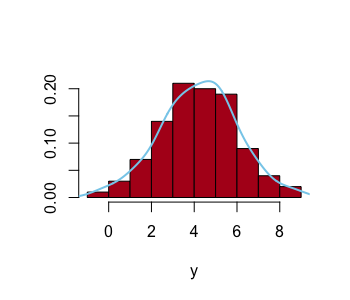 |
| Histogram of 100 random numbers drawn from N(4,2). |
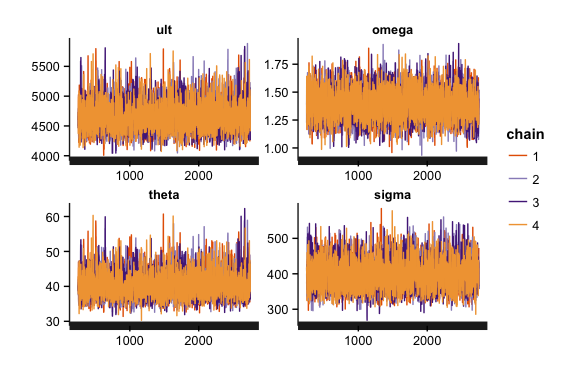 |
| Traceplot of 4 chains, including warm-up phase |
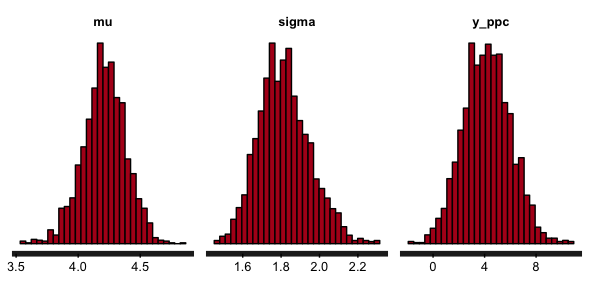 |
| Histograms of posterior parameter and predictive samples |
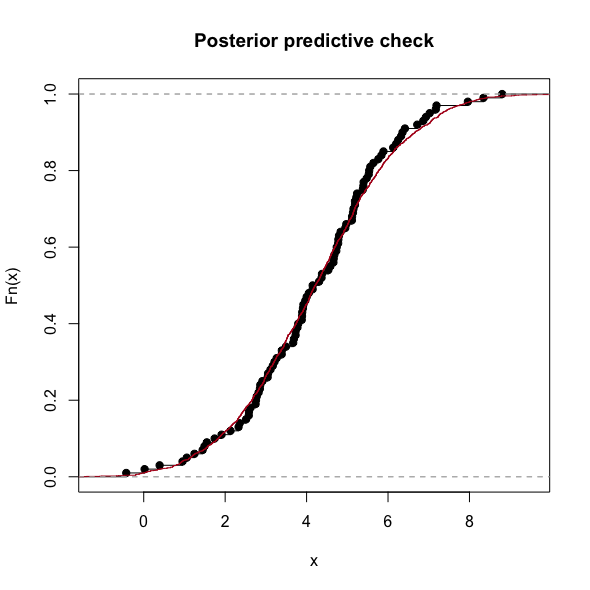 |
| Comparison of the emperical distributions |
y_ppc) is wider, taking into account the uncertainty of the parameters. The interquartile range and mean of my initial fake data and the sample of the posterior predictive distribution look very similar. That’s good, my model generates data, which looks like the original data.Bayesian Mixer Meetup
Btw, tonight we have the 4th Bayesian Mixer Meetup in London.Session Info
R version 3.3.1 (2016-06-21)
Platform: x86_64-apple-darwin13.4.0 (64-bit)
Running under: OS X 10.12 (Sierra)
locale:
[1] en_GB.UTF-8/en_GB.UTF-8/en_GB.UTF-8/C/en_GB.UTF-8/en_GB.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] MASS_7.3-45 rstan_2.12.1 StanHeaders_2.12.0 ggplot2_2.1.0
loaded via a namespace (and not attached):
[1] Rcpp_0.12.7 codetools_0.2-14 digest_0.6.10 grid_3.3.1
[5] plyr_1.8.4 gtable_0.2.0 stats4_3.3.1 scales_0.4.0
[9] labeling_0.3 tools_3.3.1 munsell_0.4.3 inline_0.3.14
[13] colorspace_1.2-6 gridExtra_2.2.1Citation
For attribution, please cite this work as:Markus Gesmann (Sep 27, 2016) Fitting a distribution in Stan from scratch. Retrieved from https://magesblog.com/post/2016-09-27-fitting-distribution-in-stan-from/
@misc{ 2016-fitting-a-distribution-in-stan-from-scratch,
author = { Markus Gesmann },
title = { Fitting a distribution in Stan from scratch },
url = { https://magesblog.com/post/2016-09-27-fitting-distribution-in-stan-from/ },
year = { 2016 }
updated = { Sep 27, 2016 }
}