Data.table rocks! Data manipulation the fast way in R
I really should make it a habit of using data.table. The speed and simplicity of this R package are astonishing.
Here is a simple example: I have a data frame showing incremental claims development by line of business and origin year. Now I would like add a column with the cumulative claims position for each line of business and each origin year along the development years.
It’s one line with data.table! Here it is:
myData[order(dev), cvalue:=cumsum(value), by=list(origin, lob)]It is even easy to read! Notice also that I don’t have to copy the data. The operator ‘:=’ works by reference and is one of the reasons why data.table is so fast.
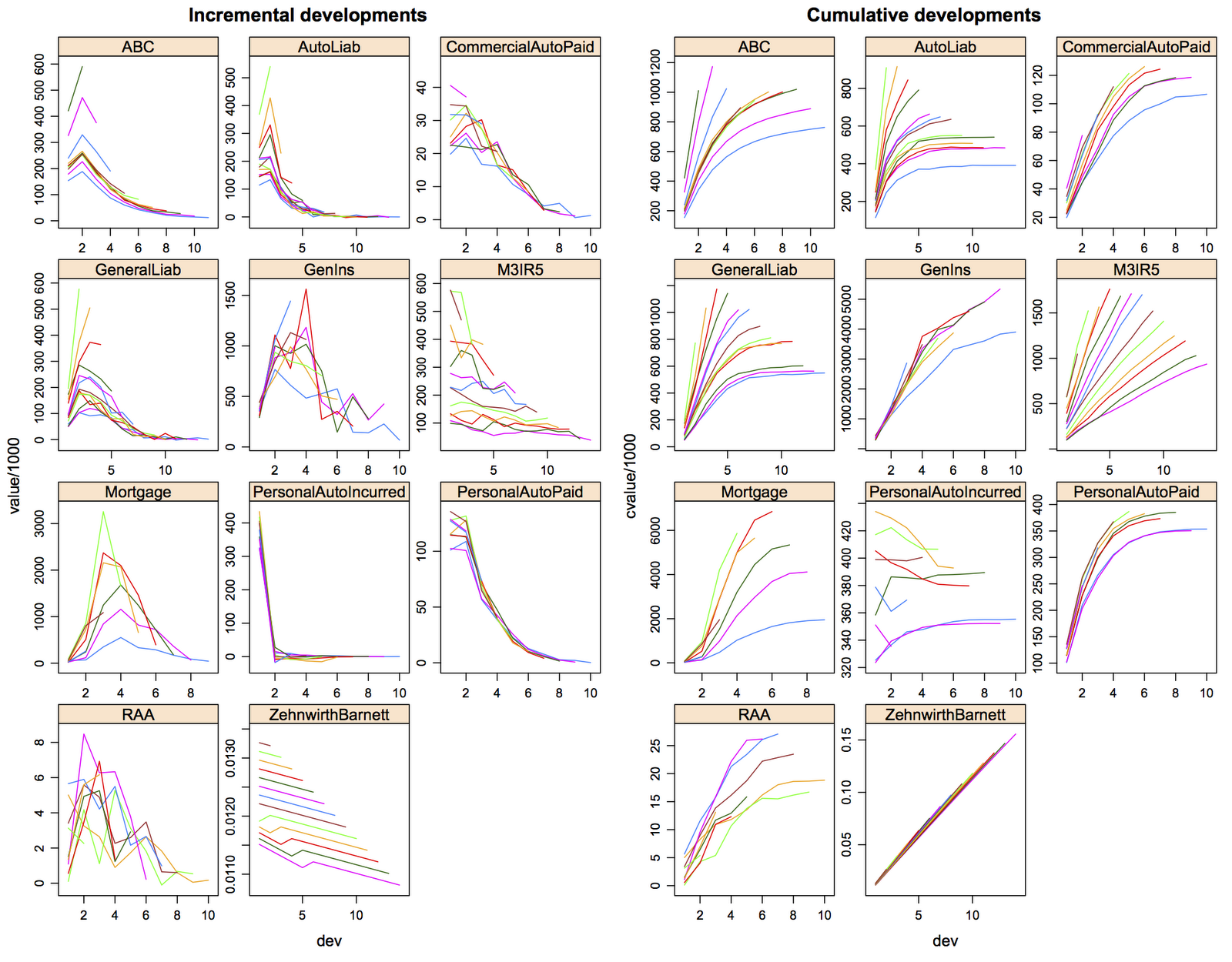 And it is getting even better. Suppose you want to get the latest claims development position for each line of business and origin year. Again, it is only one line:
And it is getting even better. Suppose you want to get the latest claims development position for each line of business and origin year. Again, it is only one line:
latestData <- myData[, .SD[max(dev)] , by=list(origin, lob)]Oh boy, I should update my ChainLadder package and utilise the power and elegancy of data.table. Many thanks to Matt Dowle and his collaborators for all their fantastic work.
Here is the R code of the examples above:
Session Info
R Under development (unstable) (2012-10-19 r60974)
Platform: x86_64-apple-darwin9.8.0/x86_64 (64-bit)
locale:
[1] en_GB.UTF-8/en_GB.UTF-8/en_GB.UTF-8/C/en_GB.UTF-8/en_GB.UTF-8
attached base packages:
[1] stats graphics grDevices utils datasets methods base
other attached packages:
[1] lattice_0.20-10 data.table_1.8.4
loaded via a namespace (and not attached):
[1] grid_2.16.0
Citation
For attribution, please cite this work as:Markus Gesmann (Nov 27, 2012) Data.table rocks! Data manipulation the fast way in R. Retrieved from https://magesblog.com/post/2012-11-27-datatable-rocks-data-manipulation-fast/
@misc{ 2012-data.table-rocks-data-manipulation-the-fast-way-in-r,
author = { Markus Gesmann },
title = { Data.table rocks! Data manipulation the fast way in R },
url = { https://magesblog.com/post/2012-11-27-datatable-rocks-data-manipulation-fast/ },
year = { 2012 }
updated = { Nov 27, 2012 }
}